On the 12th of April 2021, two members of the SanDAL team namely, Prof. Yannick Baraud and Dr. Guillaume Maillard, were invited to give a talk to the “Séminaire Parisien de Statistique”, a seminar that brings together all mathematicians who work in Paris and its suburbs. The SanDAL team is proudly contributing to the recognition of the University of Luxembourg by its French peers in the field of mathematics and statistics. The SanDAL speakers did a 75-minutes presentation each, on the following topics:
Yannick Baraud: How to build a robust estimator for a given loss?
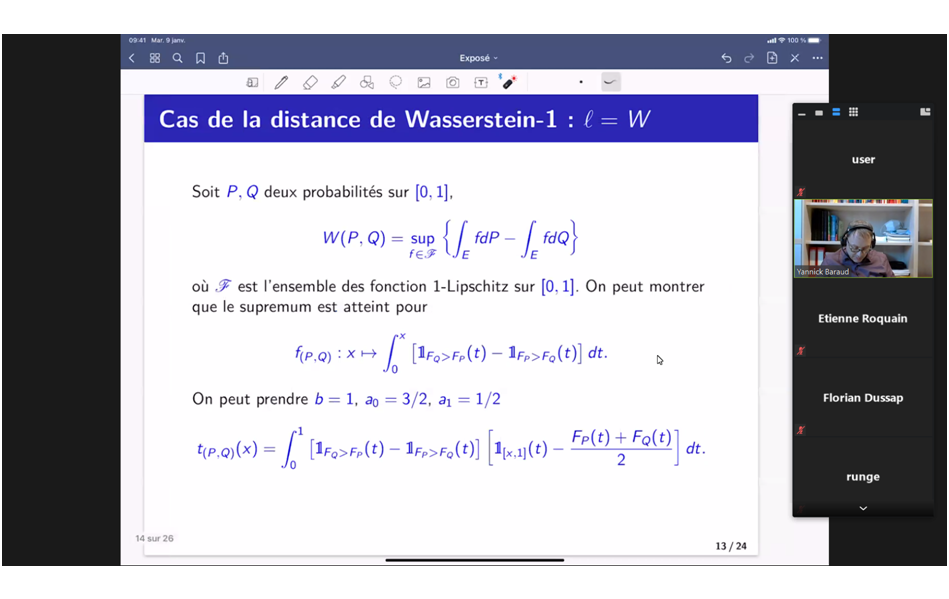
Abstract: Given an n-sample of unknown distribution, a probability model (not previously containing the distribution in question) and a loss function, we will describe a generic method allowing to build an estimator of this distribution with values in the model and whose risk, for the considered loss, is limited by the sum of two terms. The first is a term of complexity of the model corresponding to the risk that we would obtain if the law really belongs to it, the second a term of approximation of the true law by the model, which gives the estimator a certain robustness property during the observation of the model law, measured according to the loss used, remains moderate. Our approach allows us to consider classical losses such as total variation, Hellinger and Wasserstein-1 distances, Kullback-Leibler divergence, L_p losses and, more generally, all losses defined by suitable variational formulas.
Guillaume Maillard: First order asymptotics of (aggregated) hold-out in least-squares density estimation
Abstract: The hold-out, or simple validation, relies on the arbitrary choice of a validation subsample, which leads to a high variance in estimator selection. Cross-validation averages the hold-out criterion over several « folds » in order to achieve a more stable choice of estimator. However, in many cases, such as k-NN, Fourier series or histograms, convex combinations are known to improve over a single estimator. This suggests aggregated hold-out as an alternative to cross-validation, which may be superior if the gains of aggregation outweigh the model selection error. However, comparing the two is a difficult task in general. The classical analysis of model selection methods, based on oracle inequalities, is not suited to fine comparisons between different methods. Instead, we establish the first-order asymptotics of the hold-out and its aggregated version in least-squares density estimation with cosine series estimators. This analysis proves that aggregated hold-out can outperform the model selection oracle by up to a constant factor, if its parameters are well chosen.
If you are interested in the “Séminaire Parisien de Statistique”, we encourage you to visit their website.